

The URL Inspection tool in Google Search Console isn’t just a checkbox for SEO professionals. It’s a direct line into how Google actually sees your page.
It shows you:
You can even run a live test to compare the current version with what’s in the index.
But most SEOs barely scratch the surface.
This guide covers seven practical ways to use the URL Inspection tool to:
You’ll also learn what this tool can’t do – and how to avoid the most common mistakes when using it.
To start using the tool, just paste the full URL into the URL Inspection bar at the top of Google Search Console.

The URL Inspection tool in Google Search Console lets you see how Googlebot crawls, renders, and indexes a specific page.
It provides both the indexed version (from the last crawl) and a live test that checks how the page looks right now. Here’s what it shows:
These data points help you understand:

Advanced SEOs use it to:
It’s one of the few tools that gives direct insight into Google’s processing, not just what’s on the page, but what Google does with it.
Below are some of the practical uses of the tool.
The most common use of the URL Inspection tool is to check whether a page is indexed and eligible to appear in Google Search.
You’ll get one of two verdicts right away:
It’s really important to know that “URL is on Google” means it can show up, not that it will show up in search results.
To actually show up in search, the content still needs to be high quality, relevant, and competitive.

Understanding how Googlebot finds, accesses, and crawls your website’s URLs is fundamental technical SEO.
The URL Inspection tool gives a lot of detailed info on this, mostly in the Page indexing section of the inspection report for a URL:

If a key page shows “URL is not on Google,” you should dig into these fields to find out why.
It could be a simple noindex tag, a robots.txt block, a redirect, or something bigger, like content Google sees as low quality.

Seeing multiple important pages not indexed?
That could signal broader issues:
Even though the tool checks one URL at a time, a smart SEO will look for these patterns that might mean a bigger, site-wide investigation is needed.
The URL Inspection tool is useful, but not perfect.
Keep these limitations in mind when reviewing indexing:

The Request Indexing button in the URL Inspection tool lets you ask Google to recrawl a specific URL.
It’s useful for getting new pages or recently updated content into the index faster, especially after fixing critical issues or launching something important.

When you submit a URL, Google adds it to its crawl queue.
But this doesn’t guarantee that the page will be indexed or show up in search results quickly.
Indexing can still take days or even weeks, and only happens if the page meets Google’s quality and technical standards.
Things to keep in mind:

This feature works best when used strategically – for priority content or after important fixes. Just requesting indexing won’t fix broken pages.
You should make sure the page:
Submitting a URL is just a request. Google still chooses whether it’s worth indexing.
The URL Inspection tool doesn’t just tell you if a page is indexed – it shows how Googlebot renders and understands the page.
This is especially useful for JavaScript-heavy sites, where critical content or structured data may only appear after rendering.
You can access this view by clicking View crawled page for the indexed version or View tested page after a live test.

Both provide a breakdown of how Googlebot sees the page, including:
If Googlebot can’t load a key script or a critical resource like CSS is blocked by robots.txt, it might render the page incorrectly or not index it at all.
Missing resources can break mobile layouts, suppress structured data, and hide important content.
The JavaScript console output (from live tests only) is a goldmine for catching errors that would otherwise go unnoticed, like:
You can also catch early signs of site issues, such as unauthorized third-party scripts or injected code.
If the rendered HTML or resource list looks unfamiliar or off-brand, it might be a clue that something deeper, like a plugin conflict or even malicious code, is affecting your site.
If your page depends on JavaScript to display key elements, run a live test.
Only then will you see JS console messages and verify that your content is actually being rendered and indexed.
For modern websites, this is one of the most important checks in your SEO toolkit.
Get the newsletter search marketers rely on.
MktoForms2.loadForm(“https://app-sj02.marketo.com”, “727-ZQE-044”, 16298, function(form) {
// form.onSubmit(function(){
// });
// form.onSuccess(function (values, followUpUrl) {
// });
});
The Test Live URL feature in Google Search Console lets you see how Googlebot interacts with your page right now, helping you validate fixes or troubleshoot urgent issues without waiting for a re-crawl.
This section provides real-time technical feedback from Googlebot’s attempt to crawl and render the live version of your page.

Here’s what the live test won’t show – important to know so you don’t misinterpret the results:

SEOs frequently make technical fixes – removing noindex, updating robots.txt, fixing server errors – but Google may not recrawl the page for days or weeks.
The live test gives immediate confirmation that the issue is resolved and the page is now technically indexable.
You can also compare the live version to the indexed version. This side-by-side view helps you answer:
For example, if the indexed version shows Blocked by robots.txt but the live test says Crawl allowed: Yes, the fix worked – you just need to request reindexing.
But if both views show the block, you’ve still got a problem.
The live test is your real-time debugging tool.
It won’t predict Google’s final indexing decisions, but it gives you a clear yes/no on whether your page is technically good to go, right now.
Dig deeper: How to fix ‘Blocked by robots.txt’ and ‘Indexed, though blocked by robots.txt’ errors in GSC
This feature helps you confirm whether Google respects your rel=canonical tag, or overrides it with a different version.
Canonicalization is a core part of technical SEO.
When you have multiple pages with similar or duplicate content (e.g., tracking URLs, filtered product pages, localized versions), you use a canonical tag to tell Google which version should be indexed and ranked.
In the Page indexing section of the URL Inspection tool, you’ll see:

If these match, great – your signals are aligned.
If not, it means Google sees conflicting signals or believes another page is more authoritative.
Google might override your canonical if:
This is especially common on ecommerce sites, where URL parameters, filters, and variants multiply quickly.
By spotting mismatches, SEOs can:
One key caveat: live tests won’t show the Google-selected canonical – you’ll only see that for already indexed pages.
Structured data helps Google understand your content, and can make your pages eligible for rich results like:
These enhanced listings can increase click-through rates and help your content stand out in search.
The URL Inspection tool shows what structured data Google has detected on a specific page and whether it’s valid.
You’ll find this under the Enhancements section when inspecting a URL.

The tool will show:
This check lets you verify that Google sees your markup correctly and spot issues that could prevent rich results from appearing.
Using the live test, you can check structured data on newly published or recently updated pages before they’re re-crawled.
This is ideal for catching issues early, especially when adding schema for SEO or conversions.
Don’t ignore warnings – they’re often low-hanging fruit. Many schema types include optional but recommended fields.
Adding those can turn a basic snippet into something more detailed, more useful, and more clickable.
For example:
While the URL Inspection tool is great for verifying what Google sees and indexed, it’s not a full validation suite. For broader schema testing:
Together, these tools help ensure your structured data is not only correct but also visible, valid, and valuable.
You can use the Rich Results Test to perform a live test on the URL you don’t control in Google Search Console.

For deep technical SEO work, one of the most valuable (and often overlooked) features in the URL Inspection tool is its ability to show you the full HTTP response headers that Googlebot received when it crawled your page.
This is accessible under View crawled page or View tested page > More info.
These headers expose exactly how the server – or any layer between your origin and Googlebot – responded.
That data can reveal or confirm:
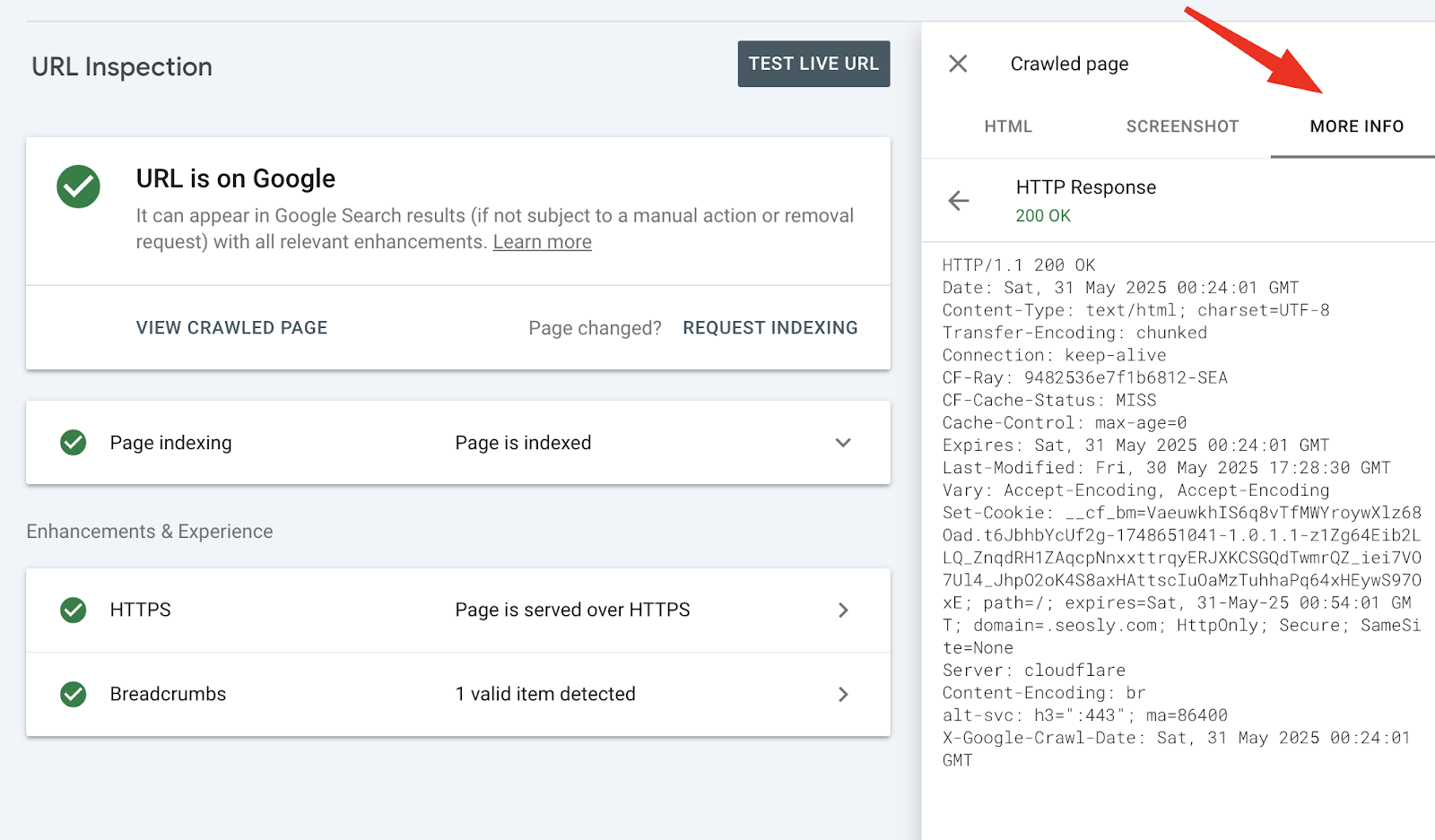
A few things you may look out for:
Header-level instructions are invisible in the source code but can significantly impact crawling and indexing.
The URL Inspection tool is one of the only ways to see what Googlebot actually received, which may differ from what you or your dev team think is being served.
Common use cases for SEOs:
While not part of indexing, headers like Strict-Transport-Security, Content-Security-Policy, X-Frame-Options, and X-Content-Type-Options can signal good site hygiene.
Google has stated these aren’t direct ranking factors, but secure, trustworthy pages support better UX, which is part of Google’s overall evaluation.
Use header data to compare Googlebot’s view with your server logs.
If they don’t match, something – likely a CDN, edge function, or reverse proxy – is changing your headers.
That misalignment can create indexing problems that are hard to detect otherwise.
If you’re doing serious SEO troubleshooting, the header data in the URL Inspection tool is a goldmine.
It’s where invisible issues hide – and where many indexing mysteries get solved.
As wonderful as it is, the tool is not a full-stack SEO analyzer.
Keep in mind that the URL Inspection tool cannot:
The bottom line: Use URL Inspection to confirm technical status for individual pages, but combine it with other Search Console reports, third-party SEO tools, and manual content reviews to get a full picture of your website.
The URL Inspection tool in Google Search Console isn’t just a checkbox for SEO professionals. It’s a direct line into how Google actually sees your page.
It shows you:
You can even run a live test to compare the current version with what’s in the index.
But most SEOs barely scratch the surface.
This guide covers seven practical ways to use the URL Inspection tool to:
You’ll also learn what this tool can’t do – and how to avoid the most common mistakes when using it.
To start using the tool, just paste the full URL into the URL Inspection bar at the top of Google Search Console.
The URL Inspection tool in Google Search Console lets you see how Googlebot crawls, renders, and indexes a specific page.
It provides both the indexed version (from the last crawl) and a live test that checks how the page looks right now. Here’s what it shows:
These data points help you understand:
Advanced SEOs use it to:
It’s one of the few tools that gives direct insight into Google’s processing, not just what’s on the page, but what Google does with it.
Below are some of the practical uses of the tool.
The most common use of the URL Inspection tool is to check whether a page is indexed and eligible to appear in Google Search.
You’ll get one of two verdicts right away:
It’s really important to know that “URL is on Google” means it can show up, not that it will show up in search results.
To actually show up in search, the content still needs to be high quality, relevant, and competitive.
Understanding how Googlebot finds, accesses, and crawls your website’s URLs is fundamental technical SEO.
The URL Inspection tool gives a lot of detailed info on this, mostly in the Page indexing section of the inspection report for a URL:
If a key page shows “URL is not on Google,” you should dig into these fields to find out why.
It could be a simple noindex tag, a robots.txt block, a redirect, or something bigger, like content Google sees as low quality.
Seeing multiple important pages not indexed?
That could signal broader issues:
Even though the tool checks one URL at a time, a smart SEO will look for these patterns that might mean a bigger, site-wide investigation is needed.
The URL Inspection tool is useful, but not perfect.
Keep these limitations in mind when reviewing indexing:
The Request Indexing button in the URL Inspection tool lets you ask Google to recrawl a specific URL.
It’s useful for getting new pages or recently updated content into the index faster, especially after fixing critical issues or launching something important.
When you submit a URL, Google adds it to its crawl queue.
But this doesn’t guarantee that the page will be indexed or show up in search results quickly.
Indexing can still take days or even weeks, and only happens if the page meets Google’s quality and technical standards.
Things to keep in mind:
This feature works best when used strategically – for priority content or after important fixes. Just requesting indexing won’t fix broken pages.
You should make sure the page:
Submitting a URL is just a request. Google still chooses whether it’s worth indexing.
The URL Inspection tool doesn’t just tell you if a page is indexed – it shows how Googlebot renders and understands the page.
This is especially useful for JavaScript-heavy sites, where critical content or structured data may only appear after rendering.
You can access this view by clicking View crawled page for the indexed version or View tested page after a live test.
Both provide a breakdown of how Googlebot sees the page, including:
If Googlebot can’t load a key script or a critical resource like CSS is blocked by robots.txt, it might render the page incorrectly or not index it at all.
Missing resources can break mobile layouts, suppress structured data, and hide important content.
The JavaScript console output (from live tests only) is a goldmine for catching errors that would otherwise go unnoticed, like:
You can also catch early signs of site issues, such as unauthorized third-party scripts or injected code.
If the rendered HTML or resource list looks unfamiliar or off-brand, it might be a clue that something deeper, like a plugin conflict or even malicious code, is affecting your site.
If your page depends on JavaScript to display key elements, run a live test.
Only then will you see JS console messages and verify that your content is actually being rendered and indexed.
For modern websites, this is one of the most important checks in your SEO toolkit.
Get the newsletter search marketers rely on.
MktoForms2.loadForm(“https://app-sj02.marketo.com”, “727-ZQE-044”, 16298, function(form) {
// form.onSubmit(function(){
// });
// form.onSuccess(function (values, followUpUrl) {
// });
});
The Test Live URL feature in Google Search Console lets you see how Googlebot interacts with your page right now, helping you validate fixes or troubleshoot urgent issues without waiting for a re-crawl.
This section provides real-time technical feedback from Googlebot’s attempt to crawl and render the live version of your page.
Here’s what the live test won’t show – important to know so you don’t misinterpret the results:
SEOs frequently make technical fixes – removing noindex, updating robots.txt, fixing server errors – but Google may not recrawl the page for days or weeks.
The live test gives immediate confirmation that the issue is resolved and the page is now technically indexable.
You can also compare the live version to the indexed version. This side-by-side view helps you answer:
For example, if the indexed version shows Blocked by robots.txt but the live test says Crawl allowed: Yes, the fix worked – you just need to request reindexing.
But if both views show the block, you’ve still got a problem.
The live test is your real-time debugging tool.
It won’t predict Google’s final indexing decisions, but it gives you a clear yes/no on whether your page is technically good to go, right now.
Dig deeper: How to fix ‘Blocked by robots.txt’ and ‘Indexed, though blocked by robots.txt’ errors in GSC
This feature helps you confirm whether Google respects your rel=canonical tag, or overrides it with a different version.
Canonicalization is a core part of technical SEO.
When you have multiple pages with similar or duplicate content (e.g., tracking URLs, filtered product pages, localized versions), you use a canonical tag to tell Google which version should be indexed and ranked.
In the Page indexing section of the URL Inspection tool, you’ll see:
If these match, great – your signals are aligned.
If not, it means Google sees conflicting signals or believes another page is more authoritative.
Google might override your canonical if:
This is especially common on ecommerce sites, where URL parameters, filters, and variants multiply quickly.
By spotting mismatches, SEOs can:
One key caveat: live tests won’t show the Google-selected canonical – you’ll only see that for already indexed pages.
Structured data helps Google understand your content, and can make your pages eligible for rich results like:
These enhanced listings can increase click-through rates and help your content stand out in search.
The URL Inspection tool shows what structured data Google has detected on a specific page and whether it’s valid.
You’ll find this under the Enhancements section when inspecting a URL.
The tool will show:
This check lets you verify that Google sees your markup correctly and spot issues that could prevent rich results from appearing.
Using the live test, you can check structured data on newly published or recently updated pages before they’re re-crawled.
This is ideal for catching issues early, especially when adding schema for SEO or conversions.
Don’t ignore warnings – they’re often low-hanging fruit. Many schema types include optional but recommended fields.
Adding those can turn a basic snippet into something more detailed, more useful, and more clickable.
For example:
While the URL Inspection tool is great for verifying what Google sees and indexed, it’s not a full validation suite. For broader schema testing:
Together, these tools help ensure your structured data is not only correct but also visible, valid, and valuable.
You can use the Rich Results Test to perform a live test on the URL you don’t control in Google Search Console.
For deep technical SEO work, one of the most valuable (and often overlooked) features in the URL Inspection tool is its ability to show you the full HTTP response headers that Googlebot received when it crawled your page.
This is accessible under View crawled page or View tested page > More info.
These headers expose exactly how the server – or any layer between your origin and Googlebot – responded.
That data can reveal or confirm:
A few things you may look out for:
Header-level instructions are invisible in the source code but can significantly impact crawling and indexing.
The URL Inspection tool is one of the only ways to see what Googlebot actually received, which may differ from what you or your dev team think is being served.
Common use cases for SEOs:
While not part of indexing, headers like Strict-Transport-Security, Content-Security-Policy, X-Frame-Options, and X-Content-Type-Options can signal good site hygiene.
Google has stated these aren’t direct ranking factors, but secure, trustworthy pages support better UX, which is part of Google’s overall evaluation.
Use header data to compare Googlebot’s view with your server logs.
If they don’t match, something – likely a CDN, edge function, or reverse proxy – is changing your headers.
That misalignment can create indexing problems that are hard to detect otherwise.
If you’re doing serious SEO troubleshooting, the header data in the URL Inspection tool is a goldmine.
It’s where invisible issues hide – and where many indexing mysteries get solved.
As wonderful as it is, the tool is not a full-stack SEO analyzer.
Keep in mind that the URL Inspection tool cannot:
The bottom line: Use URL Inspection to confirm technical status for individual pages, but combine it with other Search Console reports, third-party SEO tools, and manual content reviews to get a full picture of your website.









